Scraping for Real Facts
With the meteoric rise of hoaxes, rumors and "alternative facts," it's more important than ever to find reliable sources of information (i.e. real facts). One reliable source is fact-checking websites. But I don't want to have to check each site multiple times a week, so I use a technique called web scraping to conveniently send the most recent updates from multiple fact-checking websites to my inbox. Oh, and BTW, it's even possible to web scrape in a way that's legal and ethical.
What is Web Scraping?
Imagine I'm an avid book reader. There are two (non-Amazon) websites where I like to order books: Betty's Books and Bob's Books. Each website has a best-seller list and I like to know what other people are reading. But I can't be bothered to visit both sites regularly. Wouldn't it be great to regularly receive both lists in my inbox?
If I'm a programmer, I can write a computer program called a web scraper to regularly retrieve the best-seller lists from both websites and send them to me via email. (Or display them on one convenient web page.)
Before scraping a list for the first time, I have to study the page's (HTML) structure to be able to tell my program: 1) what web page the list is on; and 2) where exactly on that page the list is located. I can then write a small program to scrape (i.e. extract) that part of the web page. Note that I'll have to do this twice -- once for each site -- because Betty and Bob hired different designers to design their websites, and therefore the two best-seller lists aren't in the same place or in the same format.
Once the scraping program "knows" which parts of the web page I'm interested in, it can be executed to retrieve those parts as often as I like. (Once a week is good; let's not overdo it.) Checking a website for new content merely requires executing the program on a regular basis, and checking to see if the list has changed.
Scraping vs Crawling
Web scraping should not be confused with web crawling. As described above, scraping requires a programmer to first analyze the page where the desired info exists.
Web crawling is used primarily by search engines (and ChatGPT). It's similar to scraping, but with important differences. A web crawler does not need to be told what to look for on a page; in fact, a crawler's main task is to analyze a page itself and guesstimate what the page's main subject(s) are. This information is used for search engine indexing. If the web crawler determines that the page is about giraffes, then it will return the page as one of the results when a user searches for "giraffe." And finally, a web crawler will typically crawl entire websites: Once it has analyzed a page, it will then repeat the process with all links to pages on the same website.
In summary, a web scraper looks for specific information on a web page, based on earlier analysis by a programmer of that page's structure. A web crawler has no prior knowledge of a page, and tries to determine the main subject(s) of the page itself before it then continues by following all the links on that page and doing the same.
Is Web Scraping Legal? Is it Ethical?
As with a lot of technologies, the use of web scraping has grown faster than laws and ethicists can keep up. However a 2022 ruling in the US has set some general guidelines about legality and ethics.
Legality
In general, web scraping is legal if:
- The owner of the scraped website does not suffer a loss from scraping. A "loss" could be a loss of competetive advantage if the scraping results in a monetary loss for the scraped site. Another kind of "loss" could be if the scraper crashes the scraped website by requesting hundreds of web pages simultaneously.
- Only public pages (i.e. pages not requiring a login) are scraped.
- No personal data is collected.
Ethics
The matter of ethics and web scraping is less clear. One could argue that being "ethical" means being open and honest about scraping, and respecting a website's wishes vis-à-vis being scraped. An example of ethical scraper behavior might include the following:
- The scraper skips pages the website does not want scraped. A webmaster can specify this in the
robots.txtfile on the website. - The scraper does not try to "disguise" itself.
A web scraper has a number of ways in which it can disguise its identity. Why would a scraper do that? Some websites actively try to identify and block web scrapers, possibly for the reasons mentioned above about competetive advantage or crashing the website. Two ways that websites identify possible scrapers are:
- a suspicious browser type (or user agent)
- many almost simultaneous requests from the same IP address
Some web scrapers will try very hard to outsmart those possible scraper-blocking measures taken by web servers.
The easier strategy is to change the identity of the program requesting a web page. A normal web browser will identify itself when it requests a web page. If I use Firefox, every website I visit knows I'm using Firefox (plus additional technical info, like my operating system, but nothing that can uniquely identify me). A web scraper that wants to fool a website into thinking it's a human being can "masquerade" as a web browser like Firefox, thus hiding its true identity as a web scraper.
The more difficult and sophisticated strategy to disguise a web scraper is to scrape a website using multiple IP addresses. This is done using proxy servers: The scraper will ask multiple servers to scrape pages on its behalf. Companies exist that offer this as a service. A web scraper will send multiple scraping requests, with the same target website, to a number of proxy servers. The target website will receive the requests from different IP addresses, thus giving the impression that the requests are coming from different users.
Fact-Check Central
In order to go from theory to practice, I created a demo called Fact-Check Central (FCC). It highlights a handful of fact-checking websites that take rumors or statements from public individuals, check those statements for accuracy, and publish the findings.
My motivation was twofold:
- To develop and demonstrate web scrapers that are (IMHO) both legal and ethical.
- To highlight the important work being done by fact-checking organizations.
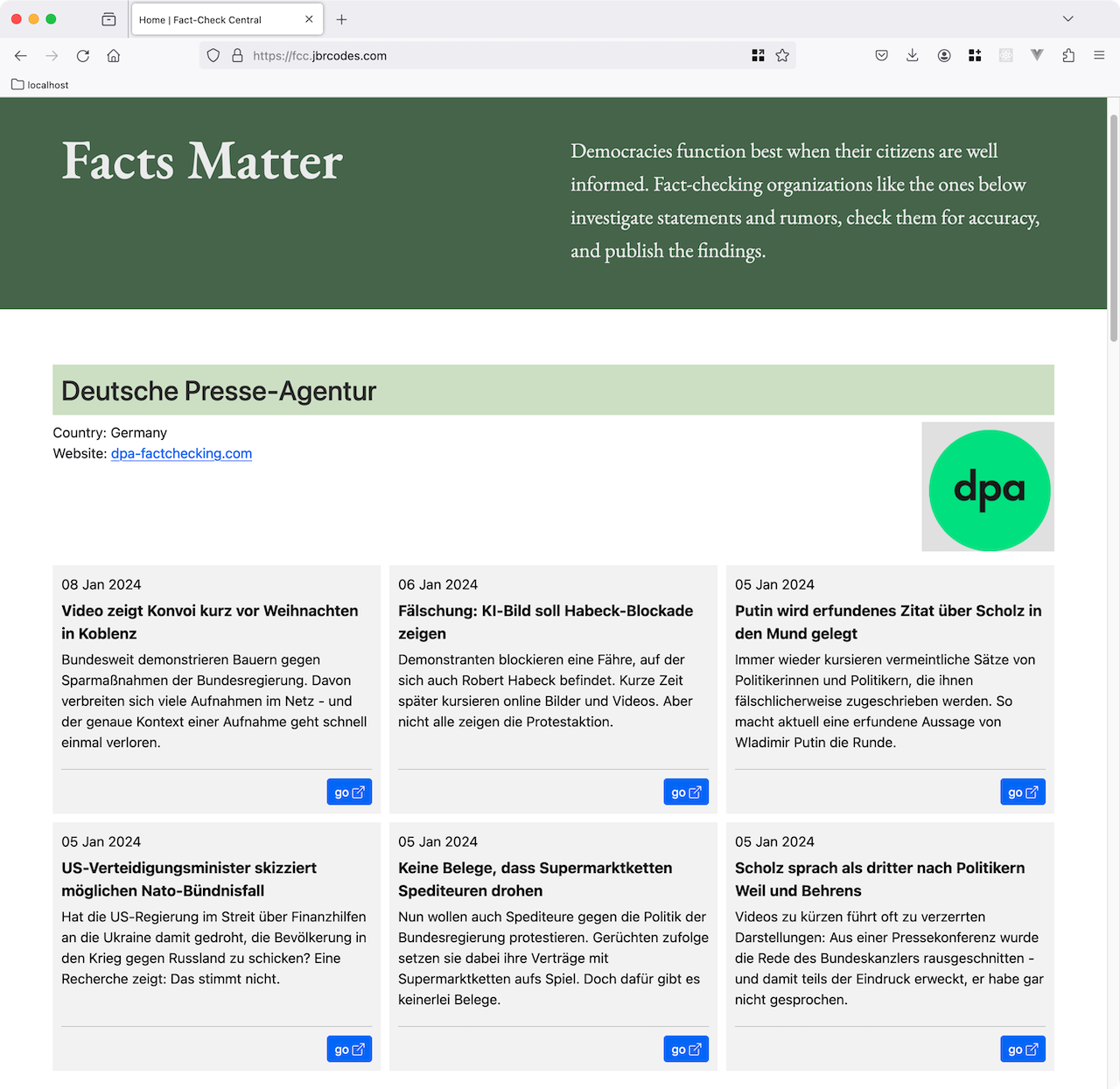
As described above, I started by choosing a few websites from a list of websites whose organizations are signatories to the International Fact-Checking Network (IFCN). I analyzed the pages that show the most recent fact-checks on each website. Each website organizes its pages differently, so I wrote a small program for each website to scrape the interesting parts: statement to be fact-checked, author, date, "truthiness" rating, etc.
The websites are scraped a few times a week (during off-peak hours). New entries are saved in a database. Only the most recent entries are shown, and clicking on an entry will take you to the original article on the fact-checking website.
Based on the criteria listed above, FCC's web scraping is both legal and ethical:
- It does not try to profit from the data it scrapes; on the contrary, it highlights the fact-checking organizations.
- It does not overload the webserver with a large number of simultaneous requests.
- It only collects publicly-available information from the pages.
- It does not request pages that are listed in the website's
robots.txtfile. - It does not try to disguise itself: It always scrapes from the same IP address, and it does not (falsely) identify itself as a web browser being used by a human.
Full disclosure: I'm curious to see if I get blocked by any of the sites that I claim I'm legally and ethically scraping. Stay tuned! 😳
[Dec 2024 Update: No blocks so far 🤞]
[Mar 2025 Update: One site has blocked me]
Technologies Used
The following technologies were used to develop Fact-Check Central: